Meta AI SAM Demo 配置安装
1.简单介绍
Meta发布首个基础图像分割模型SAM(SegmentAnythingModel)。
SAM已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成掩码,甚至包括在训练过程中没有遇到过的物体和图像类型。
SAM足够通用,可以涵盖广泛的用例,并且可以在新的图像领域上即开即用,无需额外的训练。
SAM 可以使用各种输入提示包括点击,框选和文字,指定要在图像中分割的内容,并且可以灵活集成其他系统。
SAM 初步验证了多模态技术路径及其泛化能力,相当于计算机视觉领域的GPT-3。
官网
github
facebookresearch/segment-anything
2.系统环境
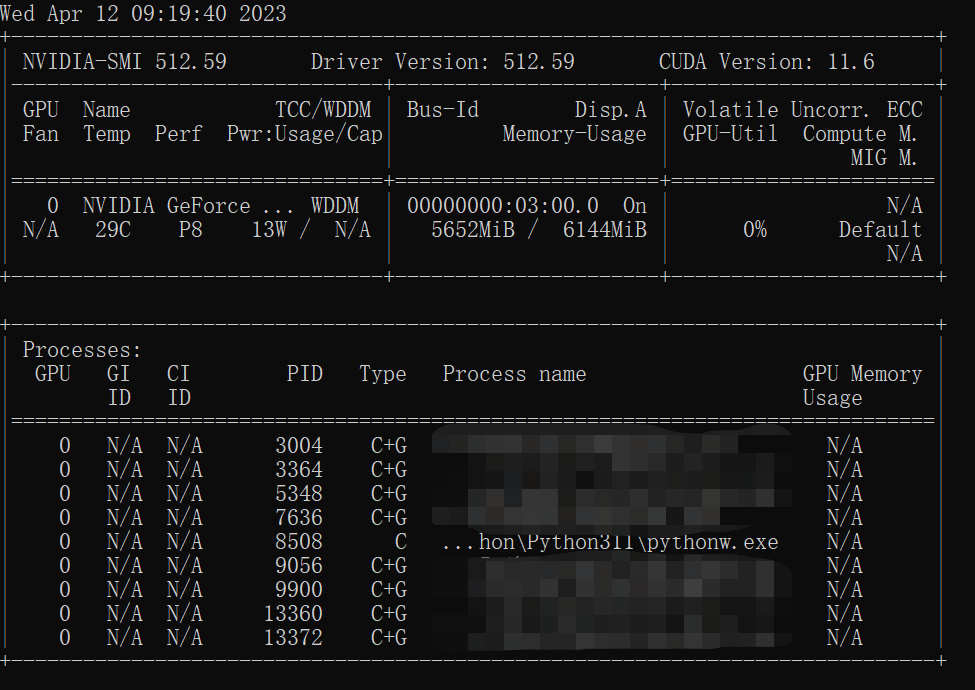
没有GPU跑不了,嗯。
笔者配置:windows10,GPU 6G;
cmd查看显存占用情况;
nvidia-smi
3.安装配置
python >= 3.8;
pytorch >= 1.7, torchvision >= 0.8;
https://pytorch.org/get-started/locally/
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
segment anything;
pip install git+https://github.com/facebookresearch/segment-anything.git
demo中用到的python库也需要安装:
cv2;
pip install opencv-contrib-python
matlab;
pip install matplotlib
jupyter;
用来把官方demo的ipynb的教程文档转成py脚本,不装也可以,手动cv一样的;
https://jupyter.org/
可以装jupyterlab,功能更新更全,不过本文档都用不到;
也可以装经典版jupyter notebook;
安装jupyterlab
pip install jupyterlab
运行jupyterlab
jupyter-lab
安装 jupyter notebook
pip install notebook
运行jupyter notebook
jupyter notebook
4.跑一下官方给的两个demo
segment-anything/predictor_example.ipynb
segment-anything/automatic_mask_generator_example.ipynb
官方提供了两个演示demo,一个是手动选取某个范围识别生成块遮罩,一个是自动识别生成图片中的块遮罩;
fork到本地后,先运行jupyter notebook把ipynb转成py文件;
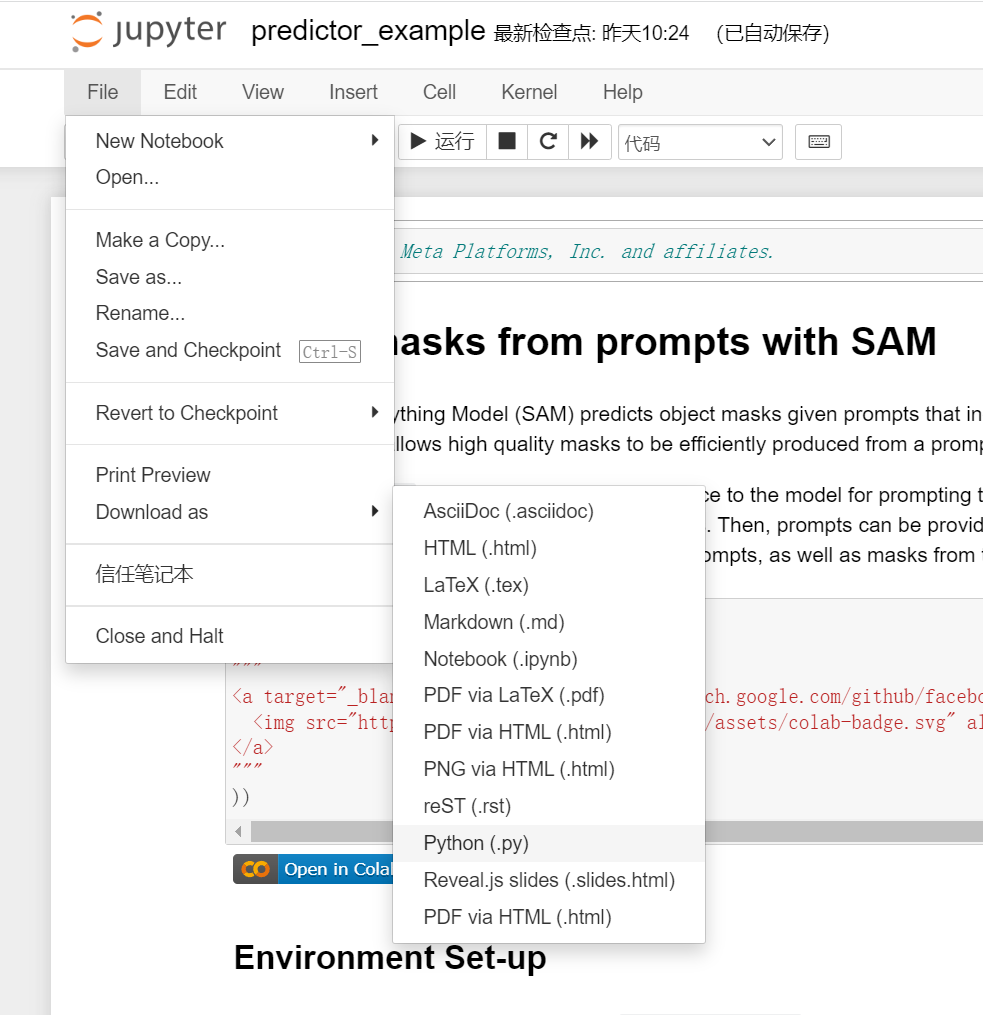
py文件直接放到ipynb同目录;
看一下py代码,需要配置两个部分:
1.图片地址,默认用demo的/images;
2.model checkpoint,官方提供了三种规模的模型;
defaultorvit_h: ViT-H SAM model.vit_l: ViT-L SAM model.vit_b: ViT-B SAM model.
如果显存不是很大,比如笔者6G,需要把py中的checkpoint换成小的vit_b;
默认的vit_h有2G多跑不起来;
model也直接放到ipynb同目录下;
# 图片路径
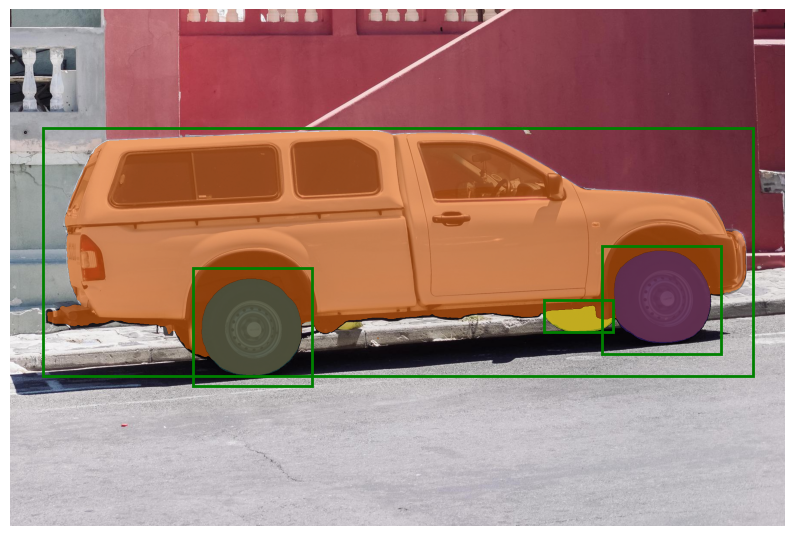
image = cv2.imread('images/truck.jpg')
# checkpoint路径
sam_checkpoint = "sam_vit_b_01ec64.pth"
model_type = "vit_b"
最后运行py文件就可以查看图片效果了。
详细运行过程不放截图了,一张关掉下一张就出来了。